Top 10 practices I hate in C++
29 September 2020

After working with C++ for the past years, I have developed some relatively strong opinions about several things people do, when writing C++. This inspired me to come up with the TOP 10 C++ practices, I hate most.
Before we begin I would like to clarify the following things:
- Aside of the top 3, all the rest are random order.
- I do not claim these practices to be inherently bad. It depends a lot on the context. Even so, in some cases I may be just expressing opinions that are more like personal preferences rather than a best practice or a “rule”. That being said, if there is a relevant C++ Core guideline I will mention it.
- I will assume there are no technical constraints keeping you from using C++11 or newer.
- The code in the examples may be oversimplified
- The pointed out issues may not be exclusive to C++
(10) Not using a range-for loop, when there is a choice
I just don’t understand why people still insist on using an incrementing index to iterate
over a collection of values instead of a ranged-for loop. That is, if and where there is a
choice of course.
I am under the impression this happens because they have been taught for loops that way, in a
Programming 101 course long ago and since then they have been instinctively using it. I find
ranged-for loops much safer and readable
// DON'T LIKE
for (std::size_t i = 0; i < v.size(); ++i)
{
std::cout << v[i] << '\n';
}
// DON'T LIKE
for (auto p = v.begin(); p != v.end(); ++p)
{
std::cout << *p << '\n';
}
// DO LIKE
for (const auto& x : v)
{
std::cout << x << '\n';
}
The first two ways of iterating over v are just… bad! You simply cannot tell what the loop actually
iterates over, just “how many times”. On the other hand, when you iterate over v using the ranged-for
loop, it becomes immediately clear that you want to do something “for every element x in v”.
The related C++ Core Guidelines is ES.71,
so whenever I see a ranged-for loop not being used during a code review, my next step is to see if it can be used instead.
(9) Manual memory management using raw pointers
Despite all the memory leaks and the bad reputation C++ has gotten from them, people just don’t learn do they?
They keep using their new operators and their malloc with total disregard of smart pointers, RAII and standard library
containers. I don’t know about you, but I instantly get very suspicious when I see these particular keywords in a modern
C++ codebase.
int main()
{
// DON'T LIKE: Raw owning pointer of Foo instance
Foo* f1 = new Foo();
// DO LIKE: the Foo instance is owned by a unique pointer
auto f2 = make_unique<Foo>();
return 0;
}
As a matter of fact, it is very rare I come across good and unavoidable usage of the so-called owning raw pointers
and memory allocation with malloc. In most cases, it involves the usage of a legacy, or simply bad, API.
Some relevant C++ Core guidelines are R.3
and R.10.
(8) Misused smart pointers ignoring conventions on lifetime & ownership
From how I see it, the C++ Core guidelines are very clear on when one should use smart pointers. More importantly, they have very well documented implications on a practical as well as a semantic level in regards to lifetime and ownership.
struct Bar
{
Bar(std::unique_ptr<Foo> f) : mFoo{std::move(f)} {}
void useFoo() { mFoo->blop(); }
private:
std::unique_ptr<Foo> mFoo;
};
int main()
{
// DON'T LIKE: Bar does not need to *own* the Foo instance
// since it does not reseat or destroy it.
// Additionally, `f` will always exist as long as `b`
// does, so no need to worry about it going out of scope.
auto f = std::make_unique<Foo>();
Bar b{std::move(f)};
return 0;
}
Typical issues I see is using a smart pointer when a raw, non-owning pointer or a reference would have been
perfectly fine. Another one is using shared pointers aimlessly without no particular excuse.
There are many rules from the C++ Core Guidelines that cover their usage such as
F.7,
R.21,
R.30 etc.
(7) Cryptic abbreviations (I don’t want to guess what they mean)
Unfortunately, weird abbreviations and acronyms are often part of the culture and one has to guess
misunderstand or awkwardly wait until a brave soul inquires about their meaning.
This trait spans across many domains and programming languages, however I have noticed it is especially
common in some low end embedded systems. Possibly a trait of C developers? Who knows! 😆

I sincerely think it’s a very bad behavior we should leave behind as soon as possible. I hope you know there is no
performance boost if you omit the vowels from a variable name, right?
There’s a very interesting read on this, by Elon Musk:
Acronyms Seriously Suck.
Please take it into consideration when writing software!
(6) Avoiding to use “auto” (Why sadistically repeat redundant types?)
To tell you the truth, my personal preference is rather on the extreme side of this. I typically like
to use auto as much as possible.
Specifically, I like to use auto only when I intend to implicitly convert the value on the right side,
for example when I want a number with a specific range or a sequence of characters as a std::string.
Parameter getParameter();
std::vector<std::vector<std::byte>> getFrameBuffer();
int main()
{
// DON'T LIKE: Isn't the type super obvious?
std::unique_ptr<Parameter> p1 = std::make_unique<Parameter>();
// DON'T LIKE: Isn't the API descriptive enough?
Parameter p2 = getParameter();
std::vector<float> numbers(10);
// DON'T LIKE: Even if it wasn't obvious, do you really need
// to know they are float? You may even end up doing an
// implicit conversion by mistake
for (float& n : numbers) { /* ... */ }
// DON'T LIKE: Use `auto` or at least an alias for the type!
std::vector<std::vector<std::byte>> fb = getFrameBuffer();
return 0;
}
You don’t have to be as extreme as me. However you should try to avoid repeating type names.
And I am not taking just about when using ranged-for loops.
I believe that if you have good API names, then by using auto your code is not only as understandable,
safe, but also easily maintainable across small API changes.
A relevant C++ Core guidelines rule is
ES.11.
(5) C-style strings and arrays (This isn’t 1998 boomer)
Frankly, I get puzzled when I still see these things in modern C++ codebases.
In regards to the C-style arrays, compared to modern standard library containers such as the
std::vector and the std::array, the difference in performance is usually insignificant. Their
elements are even continuously stored in memory so you can always fall back to a pointer.
Same goes for std::string.
The most important advantage of the modern data structures, aside of making your life easier with their
extra features, is the readability and safety they offer.
void someLowLevelAPI(char* payload);
int main() {
// DON'T LIKE: Use a std::vector or std::array
int temperatures[7] = {-10, -5, 0, -2, 4, 6, 0};
// DON'T LIKE: Just don't, we have beautiful std::string now
char* name = "Dimi";
char name[] = {'D', 'I', 'M', 'I', '\0'};
someLowLevelAPI(name);
// DO LIKE: std::string's are so much easier, safer, fancier
std::string name{"Dimi"};
someLowLevelAPI(name.c_str());
return 0;
}
In case you “need” to use an C-style array or character pointer because of a legacy or external API
that utilizes those types then my suggestion would be to use their modern equivalents and convert to the
legacy types only when you invoke the API that needs them.
Some of the related C++ Core guidelines are R.14
and SL.str.1.
(4) Old style casting does look better but let’s stop doing it
Ideally, you’d want to avoid casts all together but there are indeed some cases where they are necessary. That being said, what you should definitely not do is C-style casts. I like their looks, however, people sometimes tend to do nasty shortcuts using them, so let’s just steer clear of them, shall we?
std::optional<int> getElement(int index)
{
static const std::vector<int> elements { 1, 2, 3, 5};
// DON'T LIKE: It may look nicer than static_cast but in the name of
// safety, let's generate warnings with -Wold-style-cast and eventually
// treat them as errors
if ((std::size_t) index < elements.size())
{
return std::make_optional(elements.at(index));
}
return std::nullopt;
}
If there’s a need to cast, then use a named cast, in which case a static_cast will be the thing you’d want
in most scenaria.
Some cast related C++ Core guidelines include
ES.48 and
ES.49.
(3) Optimizing for “performance” and other excuses to write unmaintainable code
This could be broken down to multiple practices, but the reason behind them can be traced back to the same cause: Someone using performance optimization as an excuse to write 💩, hard to test and error-prone software.
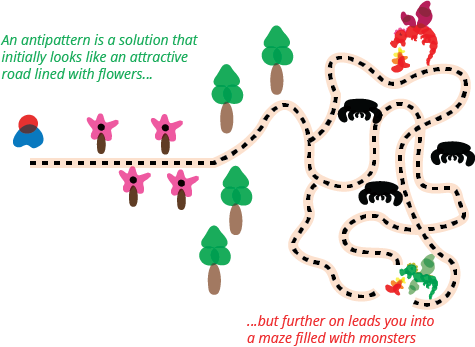
First of all, Worse is better.
If you want to optimize something, the first question you need to ask yourself is if this makes sense
from a business perspective. Does this bring value to your product or component?
You can discover this by defining one or more quantifiable metrics you want to improve.
Then you need to prove the relation of this metric to the perceived value of your product offering. For example,
you can set up an experiment with your users to verify if loading a screen 20 milliseconds faster, improves their experience.
After you have formulated your optimization goal and mapped it to the business, you want to measure how does your system
currently perform in regards to the particular metrics. You will end up with a difference, a delta.
Is this delta considerable enough to warrant action on this?
Is a solution that increases the technical debt of your system, by the business gains?
It may be so, but before you make any decisions that are detrimental to the sustainability of your product,
do ask yourselves all these questions.
Evaluate the implications before adopting a singleton pattern, not using modern C++ or utilizing your own
implementation of a standard library container just because you think it “suits your needs better” etc. 😅
Naturally, there aren’t any C++ Core guidelines for this, but instead, I encourage you to adopt the
3 rules of optimization.
(2) Abstractions leaking details (Coupling to implementation defeats their purpose)
When you come to think of it, it’s an oxymoron, isn’t it?
An abstraction is meant to, abstract, generalize and be implementation agnostic.
Once your abstract class starts giving clear hints on the underlying implementation, then you have essentially
lost the benefits of using an abstraction.
You start coding against the interface and not the implementation only in name and not in practice.
You violate the Liskov substitution principle
and therefore you hurt the reusability of your code.
You claim to follow object oriented programming best practices but… you actually don’t. You are simply an imposter! 😱
OK, I may be kidding, but honestly this is an indication of a bad design. If not already, you will face its consequences
very soon.
struct Camera
{
// DON'T LIKE: cv::Mat of OpenCV is an implementation-specific detail
virtual cv::Mat getFrame() = 0;
};
struct HardwareAbstractionLayer
{
// DON'T LIKE: The layer is NOT agnostic, it implies Arduino is used
virtual void pinMode(int pin, int mode) = 0;
virtual void digitalRead(int pin) = 0;
virtual int digitalWrite(int pin) = 0;
};
There are two ways of leaking details through an abstraction.
- Using implementation specific types for the return value or the function arguments.
For example, having a supposedly agnostic Camera interface with agetFramefunction that returns an OpenCV matrix, does constrain you, well, in using OpenCV matrices for handling the frames! My suggestion would be to use something more generic, such as avectorofbytesor your own implementation-agnostic structure, to be able to switch among implementations that utilize different computer vision libraries. - Exposing an underlying implementation by having the abstraction mirror its API.
When creating an abstraction, the interface is supposed to reflect the business value its consumer should expect. The abstraction is generalized so that the different concrete classes that specialize it can be utilized seamlessly by the consumers. By creating a very thin and supposedly abstract wrapper over an existing concrete implementation, does not allow you to reap the benefits of using an abstraction, because well, you simply aren’t.
Take a look at theHardwareAbstractionLayerinterface. Its name implies that it abstracts hardware, so that higher-level components don’t care what kind of platform we are running on. However, if you pay close attention and you are familiar with the Arduino library, you will notice that the various function names imply that Arduino should be used underneath.
As a result, if we wanted to migrate our higher-level components to another platform we would have to adapt the particular hardware drivers to conform to the Arduino API and its constraints. Considering the the Arduino library was first created to be used on 8-bit microcontrollers, having to use that very same API on ax86_64machine, could be severely constraining.
Similarly, let’s assume we want to do Inter Process Communication and want to create an implementation agnostic interface that can work on different machines with different IPC mechanisms. If our abstraction simply mirrors a specific API, let’s say that of D-BUS, then once we want to switch to another IPC software, it would be difficult to adjust our supposedly platform independent higher-level components that are consuming the, D-BUS inspired, abstraction.
Overall, if your goal is to create abstractions, then make them abstract. Let them be general. Don’t reflect a particular
implementation in the exposed types or functions.
If you do that you will be doing exactly what you wanted to avoid: Effectively coupling the your high-level functionality to a concrete lower-level implementation.
Naturally, since this is more of a design concern, there isn’t an explicit C++ Core guidelines rule about this. However, I do
find the following somewhat relevant as they imply that abstract classes should be generic:
I.25,
C.121.
(1) Interface names with prefixes (Unnecessary tautology implying bad design)
This is my absolute worst nightmare when it comes to C++!
I am talking about this I before an abstract class name or an Interface in the end.
Seriously, unless you are developing code for an existing framework that is already using this bad convention
then you should simply just STOP doing this.
Especially taking into consideration the drawbacks which will be illustrated below, there is literally
NO GOOD ENOUGH reason to put something in a class’ name to indicate it is an abstract interface.
The first question is, why should you care?
If you would like to use a class and want to find its abstract base, then simply look at what it is inheriting.
It saves you little to NO TIME to have an I prefix before it.
I have YET to find a good argument on supporting this very bad practice. Every book and article I have seen on the topic,
advises against it, yet in every project I have been in, people just do it.
Overall, the consumer of an abstraction, shouldn’t care it’s using an abstraction and, similarly, a class that is specializing
an interface, typically already knows its parent is an abstraction.
However, the biggest problem isn’t in the name itself.
// DON'T LIKE: Tautology
// DON'T LIKE: Why should the user of IFoo care it's an interface?
struct IFoo
{
virtual void bar() = 0;
};
// DON'T LIKE (and happens too often): No generalization!
// The fact that a particular Camera sensor offers GPS coordinates
// does not mean they all do.
struct ICamera
{
virtual Coordinates getGPSCoordinates() = 0;
virtual Image getFrame() = 0;
};
// DON'T LIKE: What happens when you get another camera?
// ICamera indicates that it should be implemented by Camera
struct Camera : public ICamera
{
Coordinates getGPSCoordinates() override;
Image getFrame() override;
};
The biggest problem with prefixing, is its consequences: Abstractions leaking details.
This usually happens when someone first creates a class, let’s say Foo.
Then, to conform to the “supposed” object oriented design of their product, they create an IFoo interface.
There, we have two issues:
- The name of the interface dictates the implementation.
IFooindicates that aFooconcrete class must be used. But… what happens if we want to have variants, let’s say aBar?
We would either have to make the naming inconsistent have aBarclass specializing theIFoointerface OR do the correct thing and find out what is the business value we want to get from those two classes. Then we’d reflect that in the interface name. So why not do the correct thing from the beginning?
However, that is not the most important problem. - The biggest concern is the specialization being created AFTER the abstraction.
Ideally, you should first identify what is the business value you want from a class, reflect that to the abstract interface in an implementation agnostic manner and then move on implementing its specializations. If you do this the other way around, you run into the risk of the concrete class influencing the supposedly generic design of your interface. For example, if you have a camera module that includes a GPS sensor, you naturally create aCameraclass with agetFrameand agetCoordinatesfunctions.
If you create anICameraclass simply by mirroring the concrete class’ API, you have implicitly made the assumption that “all camera modules must have a GPS sensor too”. An application specific detail just made it into the generic/domain logic!
To summarize, this is why I hate prefixes and suffixes indicating a class is an interface:
- This extra notation is meaningless, redundant and verbose, causing inconsistencies in naming schemes.
- It results in abstractions leaking implementation details. This is observed on two levels:
- On a semantic level
If you have anIFoo, then the name implies that the implementation is, well…Foo! So whoever is using theIFoointerface, already knows/suspects thatFoowill be used as the implementation. - On a practical/design level
To be fair, this is not necessarily always the case but I have seen it happen over and over:
Interfaces that come with a prefix to point out they are interfaces, are typically created after the concrete implementation. Therefore, they are made to mirror the concrete API. When someone designs the abstraction after the specialization, they are prone to insert implementation-specific details into the design of the supposedly implementation-agnostic API of the abstraction.
- On a semantic level
Youtube
This article also exists as a video form on YouTube. Feel free to smash the Like button, share the video and subscribe to my channel! 🎉
